Examples¶
These examples demonstrate the usage of some functions in spykeutils. This includes the creation of a small Neo object hierarchy with toy data.
Creating the sample data¶
The functions in spykeutils work on electrophysiological data that is represented in Neo object hierarchies. Usually, you would load these objects from a file, but for the purpose of this demonstration we will manually create an object hierarchy to illustrate their structure. Note that most functions in spykeutils will also work with separate Neo data objects that are not contained in a complete hierarchy. First, we import the modules we will use:
>>> import quantities as pq
>>> import neo
>>> import scipy as sp
We start with some container objects - two segments that represent trials and two units (representing neurons) that produced the spike trains:
>>> segments = []
>>> segments.append(neo.Segment('Trial 1'))
>>> segments.append(neo.Segment('Trial 2'))
>>> units = []
>>> units.append(neo.Unit('Unit 1'))
>>> units.append(neo.Unit('Unit 2'))
We create some analog signals from a sine wave with additive Gaussian noise, four signals in each segment:
>>> wave = sp.sin(sp.linspace(0, 20*sp.pi, 10000)) * 10
>>> for i in range(8):
... sig = wave + sp.randn(10000) * 3
... signal = neo.AnalogSignal(sig*pq.uV, sampling_rate=1*pq.kHz)
... signal.segment = segments[i%2]
... segments[i%2].analogsignals.append(signal)
And some spike trains from regular intervals or random time points:
>>> trains = []
>>> trains.append(neo.SpikeTrain(sp.linspace(0, 10, 40)*pq.s, 10*pq.s))
>>> trains.append(neo.SpikeTrain(sp.linspace(0, 10, 60)*pq.s, 10*pq.s))
>>> trains.append(neo.SpikeTrain(sp.rand(50)*10*pq.s, 10*pq.s))
>>> trains.append(neo.SpikeTrain(sp.rand(70)*10*pq.s, 10*pq.s))
Now we create the relationships between the spike trains and container objects. Each unit has two spike trains, one in each segment:
>>> segments[0].spiketrains = [trains[0], trains[2]]
>>> segments[1].spiketrains = [trains[1], trains[3]]
>>> units[0].spiketrains = trains[:2]
>>> units[1].spiketrains = trains[2:4]
>>> for s in segments:
... for st in s.spiketrains:
... st.segment = s
>>> for u in units:
... for st in u.spiketrains:
... st.unit = u
Now that our sample data is ready, we will use some of the function from spykeutils to analyze it.
PSTH¶
To create a peri stimulus time histogram from our spike trains, we call spykeutils.rate_estimation.psth(). This function can create multiple PSTHs and takes a dicionary of lists of spike trains. Since our spike trains were generated by two units, we will create two histograms, one for each unit:
>>> import spykeutils.rate_estimation
>>> st_dict = {}
>>> st_dict[units[0]] = units[0].spiketrains
>>> st_dict[units[1]] = units[1].spiketrains
>>> spykeutils.rate_estimation.psth(st_dict, 400*pq.ms)[0]
{<neo.core.unit.Unit object at 0x...>: array([ 6.25, 5. , 5. , 5. , 3.75, ...
spykeutils.rate_estimation.psth() returns two values: A dictionary with the resulting histograms and a Quantity 1D with the bin edges.
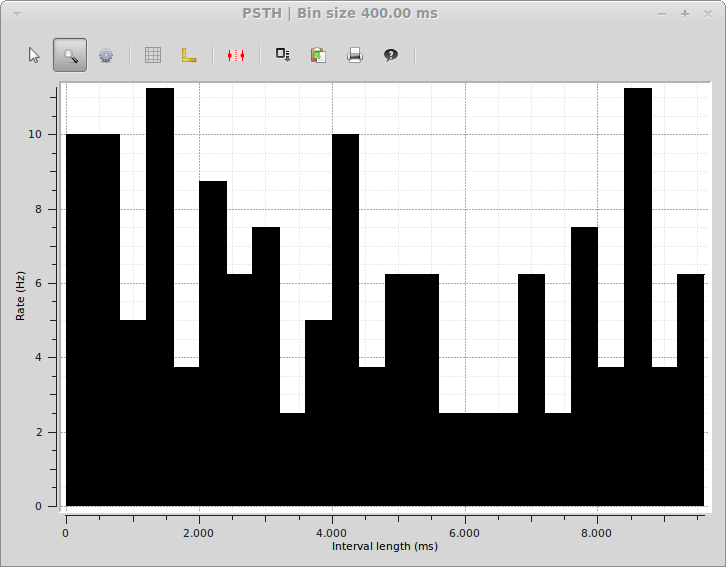
If guiqwt is installed, we can also use the spykeutils.plot package to create a PSTH plot from our data (in this case we want a bar histogram and therefore only use spike trains from one unit):
>>> import spykeutils.plot
>>> spykeutils.plot.psth({units[1]: units[1].spiketrains}, bin_size=400*pq.ms, bar_plot=True)
This will open a plot window like the following:
Spike Density Estimation¶
Similar to a PSTH, a spike density estimation gives an esimate of the instantaneous firing rate. Instead of binning, it is based on a kernel convolution which results in a smoother estimate. Creating and SDE with spykeutils works very similar to creating a PSTH. Instead of manually choosing the size of the Gaussian kernel, spykeutils.rate_estimation.spike_density_estimation() also supports finding the optimal kernel size automatically for each unit:
>>> kernel_sizes = sp.logspace(2,3.3,100) * pq.ms
>>> spykeutils.rate_estimation.spike_density_estimation(st_dict, optimize_steps=kernel_sizes)[0]
{<neo.core.unit.Unit object at 0x...>: array([ 5.05428068, 5.06979364, 5.08530387, ...
As with the PSTH, there is also a plot function for creating a spike density estimation. Here, we use both units because the function produces a line plot where both units can be shown at the same time:
>>> spykeutils.plot.sde(st_dict, maximum_kernel=1500*pq.ms, optimize_steps=100)
The resulting plot will look like the following:
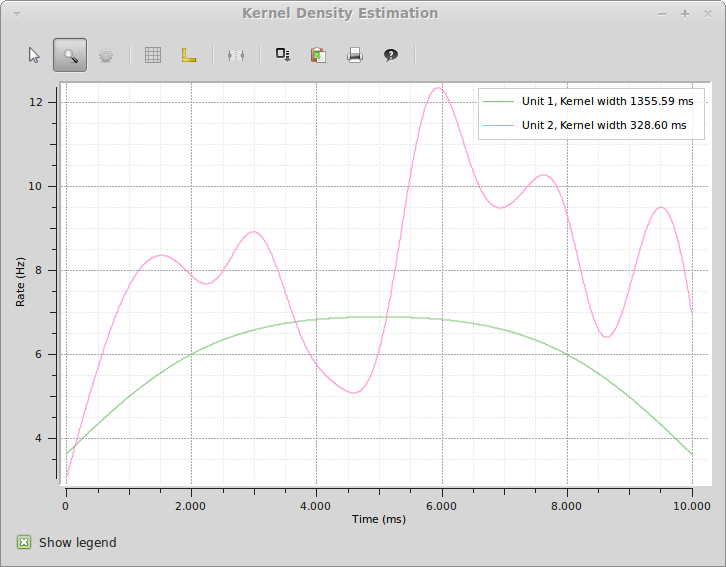
While spike density estimations are preferable to PSTHs in many cases, the picture also shows an important weakness: The estimation will generally be too low on margins. The areas where this happens become larger with kernel size, which is clearly visible from the rounded shape of Unit 1 (which really has a flat rate) with its very large kernel size.
Signal Plot¶
As a final example, we will again use the spykeutils.plot package to create a plot of the signals we created. This plot will also display the timings of our spike trains.
>>> spykeutils.plot.signals(segments[0].analogsignals, spike_trains=segments[0].spiketrains, show_waveforms=False)
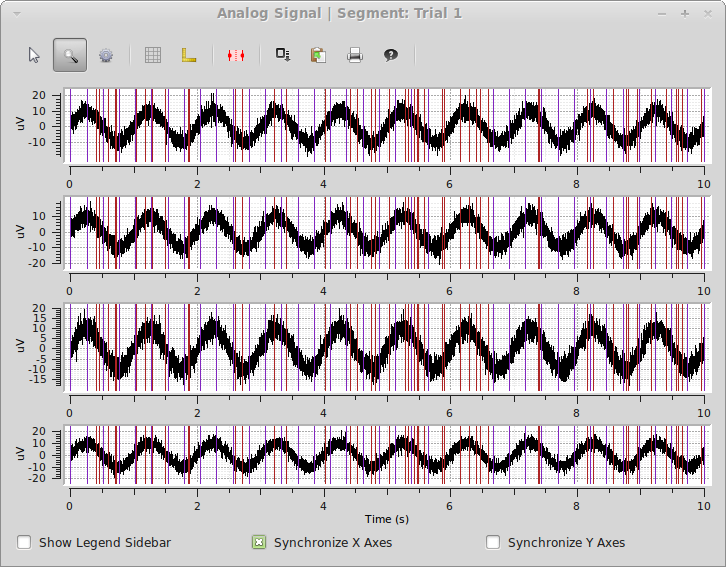
The plot shows all four signals from the first segments as well as the spike times of both spike trains in the same segment.